I was recently working through a series of coding puzzles, and came across one that asks you to write a function that takes a string and produces every possible permutation of its letters. So “abc” could be “abc”, “acb”, “bac”, “bca”, “cab”, “cba”. The book where I found the puzzle had an example of how to solve the problem in Java:
12345678910111213
void permute( String str ){
int length = str.length(); boolean[] used = new boolean[ length ]; StringBuffer out = new StringBuffer(); char[] in = str.toCharArray();
doPermute( in, out, used, length, 0 ); }
void doPermute( char[] in, StringBuffer out,
boolean[] used, int length, int level ){
if( level == length ){ System.out.println( out.toString() ); return;
}
for( int i = 0; i < length; ++i ){ if( used[i] ) continue;
out.append( in[i] );
used[i] = true;
doPermute( in, out, used, length, level + 1 ); used[i] = false;
out.setLength( out.length() - 1 );
} }
I was halfway through working through the problem in Ruby, when it occurred to me that Ruby might have an easier way of doing things. It does. It has a permutate method that allows us to solve the problem with one line of code. Behold:
I’ve been doing the Ruby katas, and last week, I completed the Roman numeral calculator, which tasks you with converting Arabic numbers to Roman numerals and vice versa. Upon completing the kata, I searched around for other answers. Imagine my surprise in finding this Rosetta Code example, which converts Arabic numbers to Roman in just a few lines of code:
1234567891011121314
Symbols = { 1=>'I', 5=>'V', 10=>'X', 50=>'L', 100=>'C', 500=>'D', 1000=>'M' }
Subtractors = [ [1000, 100], [500, 100], [100, 10], [50, 10], [10, 1], [5, 1], [1, 0] ]
def roman(num)
return Symbols[num] if Symbols.has_key?(num)
Subtractors.each do |cutPoint, subtractor|
return roman(cutPoint) + roman(num - cutPoint) if num > cutPoint
return roman(subtractor) + roman(num + subtractor) if num >= cutPoint - subtractor and num < cutPoint
end
end
[1990, 2008, 1666].each do |i|
puts "%4d => %s" % [i, roman(i)]
end
My answer was, let us say…not that efficient. So I set out to understand how the more efficient answer works.
All right. We start with a hash that matches up the standard associations (1=I, V=5, etc). We then pass these to the roman function below. The first line in the function delivers matches when a number exactly matches a symbol (i.e. x=10):
1
return Symbols[num] if Symbols.has_key?(num)
This is actually how every Roman numeral gets assigned – when the function sees a number it has a letter for, i.e. 10=X, it assigns the correct letter. It’s easy to see how this works with numbers like 10, but most Roman numbers are compilations of several letters i.e. XV=10+5, 15. To complicate matters, certain numbers, like 4, are represented by placing a smaller number to the left of a larger number, indicating that the reader should subtract by the smaller number. For example, IV= 5-1, 4. The function deals with all this logic in 4 lines of code:
1234
Subtractors.each do |cutPoint, subtractor|
return roman(cutPoint) + roman(num - cutPoint) if num > cutPoint
return roman(subtractor) + roman(num + subtractor) if num >= cutPoint - subtractor and num < cutPoint
end
It’s recursive as all getout. The code begins by iterating through the series of arrays nested in the Subtractors array. The function refers to the first element of each nested array as a “cutPoint”. The cutPoint represents the “normal” value (for example, 10). The second element indicates, referred to as the “subtractor”, is the amount that number would have to be reduced by if a “reducing” letter appeared to its left (for example IX= 10-1, 9). Essentially, the function iterates through the array, and begins doing calling itself on itself as soon as it finds a number smaller than the cutPoint. Let’s check it out with an example:
If I feed the number 11 into the function, this is what happens:
The function sees that 11 isn’t in the Symbols, and goes on to the first line of the roman function. roman goes through its array of Subtractors, and finds that 11 is less than 10. It then does the following wizbang math:
1
return roman(cutPoint) + roman(num - cutPoint) if num > cutPoint
By calling itself on itself, we get this:
calling roman(cutPoint) will call the Roman numeral-assigning first line,
1
return Symbols[num] if Symbols.has_key?(num)
to look up the cutPoint, 10, in the Symbols hash. It will give us its value, X. We do this again when we want to add the I to the next line in the code,
1
roman(num - cutPoint)
This calls the same function on 11-10, or 1. That gives us X+I, which is the correct Roman number value. Because the function keeps calling itself, and adding numerals, it also works for much larger numbers – i.e. 153 = CLIII. Most of our conversion is done with this line.
So what’s up with the second line of code? We’re actually calling it every time, but it only runs when certain conditions are met:
1
num >= cutPoint - subtractor and num < cutPoint
When do these conditions apply? Well, as luck would have it, only when we need to place a Roman numeral to the left. For example, the number 4 in roman numbers is IV. If we pass 4 into our function, it dutifully interates through cutPoints until it gets to 5. Using 5 and 4, we find that our number meets the criteria above and runs the code. 4>=(5-1) AND 4<5. It’s in this case only that the rest of the code runs:
While checking out the Ruby katas, I came across a puzzle that involved comparing two arrays, and was on the verge of writing long, convoluted if statements when it occurred to me that any language as elegant as Ruby must have better ways of doing things. Indeed it does. For example:
Check to see if 2 arrays have any matches, in 3ish lines of code
Puttering about the Internet a litte bit, I also found this post in Japanese. I could read only the code, but it’s there that I discovered mass shuffling. For example,
12
array1<<"a horse"<< "a truck" =
["Cookie Monster", "Big Bird", "Grover", "a horse", "a truck"]
The final trick I learned lets you autogenerate an array of a range of numbers. To whit:
Most of it has to do with not reinventing the wheel. What we think of as the web’s underpinnings was created by Woodstock-era American engineers and later spread to engineers and scientists in England and Europe, where it reached an audience that wrote in the Roman alphabet, and was largely comfortable with English. It didn’t become interesting to a larger audience until the early 90s, when Briton Tim Berners-Lee invented HTML, an accessible language that allowed relatively non-technical people to create and read pages on the web without typing lots and lots of things into a command line.
When Tim Berners-Lee began inventing HTML code, he didn’t start by creating a new spoken language and a new alphabet. He used what he already knew and had available, in this case, the English language and alphabet. HTML code, as well as nearly every other computer language used online, is based on English words typed on a Roman keyboard. HTML is mostly English words, or parts of English words, typed inside brackets. This remains true for other languages today. For example, the code for blinking text is the word <blink>. The code for bold text was originally the word <bold>, often shortened to <b> and later inexplicably changed to <strong>. When developers from non-Western countries want to create Web pages, they must write code written in Roman text based on the English language. This is not as difficult as it sounds; because so much computing technology originated in the West, many computer keyboards in non-Western countries consist of roman letters with local characters added.
What does this mean? Well, perhaps it means that the world is even more geared towards English than previously thought. And with it, the web. For example, languages written in the Roman alphabet read left-to-right. People who read western languages are primed to write code left-to-right. That’s why Ruby contains things like <%stuff.each do |s|%> puts s<%end%> , which only makes sense when read left-to-right, instead of <%end%> puts s <%stuff each do|s|%>, which only makes sense when read right-to-left. There’s nothing inherently better about considering things starting from the left or the right, or indeed from the top or the bottom, but people who were building the structures on which the Internet rests set it up this way because they based their decisions on what they already knew.
I originally investigated this issue at the behest of an international law professor with an anthropology background who wanted me to learn what “biases are built into the web”. I’d initially thought there weren’t any, that the web was a just and utopian place. I initially searched for academic articles on the Internet in world affairs. They barely existed, and roughly half of those that did exist were written by Columbia’s Tim Wu. (Thanks, Tim!) I finally realized that
I could simply take a sampling of foreign newspapers and read their source code online. And with it, I found a number of comments to fellow programmers in characters I could not understand at all, as well as lots and lots of HTML, which I could read perfectly well because they were in essentially in English.
I’m not really sure where this leaves us – there have been fabulous advances in technology since HTML was invented, almost all of which have built on the Romanji, left-to-right technology, and there’s clearly no going back. Still, it’s worth considering what’s been lost. For example, it only became possible to write URLs in non-Roman characters in 2010. I tried to visit a web page that Tech Crunch linked to as an example of a non-Roman url, but could not, because the reviewer did not understand the address and so entered it as a relative link.
For my team’s presentation to the Ruby meetup, we’ve been working on an app that will help people navigate NYC’s Citibike program, using a mashup of Google maps and Citibike’s publicly available JSON location data. By way of navigation, the JSON includes street address, latitude, and longitude of each location.
Our initial prototype let users pick start and end points from a dropdown menu of Citibike locations and mapped the distance between them on the map. This was hardly ideal – very few people orient themselves in a city on the basis of bike locations – so one of the first things we wanted to give users was the ability to input a street address and have the app automatically find the Citibike stations around them.
It was a sensible idea, albiet one I had no idea how to implement. It was then that my groupmate discovered this implementation of a Citibike/Google maps mashup that does exactly that. Thanks, Internet! We found this in the JavaScript source code:
12345678910111213141516171819202122
function getDistance(lat1,lng1,lat2,lng2) {
var i = lat1 - lat2;
var j = lng1 - lng2;
return i*i + j*j;
}
function findNearestStation(lat,lng) {
var min_distance = 99999;
var closest_station_id;
$.each(stations.stationBeanList, function(i, station) {
var distance = getDistance(lat,lng, station.latitude, station.longitude);
if (distance < min_distance) {
min_distance = distance;
closest_station_id = i;
}
});
console.log('Closest station idx: ' + closest_station_id);
return stations.stationBeanList[closest_station_id];
}
I’d expected a massive operation, and this was breathtakingly simple. It simply loops through all the stations, gets each one’s latitude and longitude, compares the current station to the closest station it has found so far. It was this “closeness” calculation that I was most interested in. JavaScript was comparing it using a numercal value, but how did it get that number? Well, it’s all figured out the closeness of the station using the 5-line getDistance function. getDistance which compares the station’s longitude and latitude to the user’s using this code:
123
var i = lat1 - lat2;
var j = lng1 - lng2;
return i*i + j*j;
Why subtract latitude from latitude and longitude from longitude? The difference between latitude a and latitude b is the distance between them. Granted, it’s a difference measured in…latitude units, but it’s a distance nonetheless, and we actually don’t need to more precision here. If the distance between my location and station x is .123 latitude units and the distance between my location and station y is .01 latitude units, then station y is closer. That’s all we need to know. “Latitude units” work perfectly well for this purpose.
The same logic works perfectly well for longitude, but I didn’t initially understand why we were returning latitude2 and longitude2, but then it hit me – latitude runs perfectly east-west, and longitude runs perfectly north-south. When they meet, they create a perfect right angle, and therefore, we can use….Pythagorean theorem. a2+b2=c2 . You can get the hypotenuse of a triangle by multiplying the lengths of its sides.
The advantage of considering the hypotenuse of our right triangles is it lets us perfectly average out our longitude/latitude differences. For example, my location may be very close latitude as a bike station but be very far away in longitude. Or it may be on a similar longitude but on a very different latitude. Or else it may be on a similar latitude and longitude. Whatever. By calculating c 2, we’re averaging out the differences.
And that alone is enough to let us calculate the distance.
Before learning of Mozilla TowTruck in class today, my experience of real time online collaboration tools had been limited to spreadsheets on Google Drive. And even that emerged recently enough that I could quickly resurrect gchats with remarks like “OMG! I CAN SEE YOU HIGHLIGHTING THAT ROW ON THE SPREADSHEET!” Working in real time on anything, at all, is still relatively new.
And now, says Mozilla Labs, it is much improved. They’ve released TowTruck, a collaboration tool that enables you to watch as another user’s key and mouse strokes on a web page in the same color-coded, user-labelled ways that Google lets you follow another user’s changes to a spreadsheet on Drive. . It was originally intended as an aid for budding web developers, which lead to its name – “TowTruck – who you call when you got stuck” . It can be installed by adding a two lines of JavaScript to a page in production, and gives users the option of communicating by text, audio chat, or video. Or at least that is the idea. I was ready to jump on the TowTruck bandwagon until I noticed that the main example links on its web site lead to 404s. Newly skeptical, I decided to scour the Internet in search of more insight.
The Results
In a nutshell, the online verdict is TowTruck looks promising, but is far from perfect. Mozilla says the system should still be considered “alpha quality” and not yet ready to be used in serious production. This excellent review that said TowTruck was indeed surprisingly easy to use. It’s easy to install, to invite collaborators, and audio quality was generally good. The text chat does indeed work across browsers and operating systems, but the audio chat between two computers gets wonky when neither computer is using Firefox. It’s presently only possible to use between two computers, and hasn’t really been tested on mobile.
The project is open source, so theoretically anyone could improve it at any time. TowTruck is similar to Google Drive because it borrows from Google Drive , which made its Real Time collaboration technology open source.
The company promises more mobile support in 2013. It’s not quite “there” yet, but if it continues to develop, this tool could be a big part of our lives, soon.
In preparation for learning Sinatra next week, I’ve gone poking through through this example of a Sinatra gem that I found on Github. It seemed the ideal first investigation. It’s simple – it’s only function is to write obnoxious text in a command line to annoy one’s coworkers ( a win in itself), and it’s named after the character Bubs from The Wire.
The structure reminds me of poking through video game folders on my computer, trying to cheat improve my technical skills. In an homage to my video game days, I decided to poke around and try to figure out as much as I could on my own.
The app has two main folders, lib and bin. Lib is clearly the folder that actually does things. Remember, this is an incredibly simple app. It contains exactly one file, which contains exactly one class, Bubs. Bubs’ main job is converting regular text into annoy-text, which it does in only one line: text.tr(‘A-Za-a1-90’, ‘A-Za z1-90’) . That’s pretty much it, except for a bit of code at the bottom designed to make annoy-text pleasant to all systems.
The bin side is dependent on some code I’ve never heard of, so I have to break my no-Google pledge and look it up. ( $stdin can be used to hold code inputted from a console, thank you Ruby Docs.) It looks entirely focused on the outside, taking content from the user, passing it to Bubs for him to work his magic, and then giving it back to the user. It’s entirely focused on the user’s perspective.
There are also a few files on the root directory. README and LICENSE seem self-explanatory, but there are more mysterious files. There’s a Rakefile, which seemed to be concerned with record keeping and checking to make sure things exist and can be connected to. There’s also a gemfile, which looks to be concerned with telling whatever interface runs Ruby Gems all it needs to know about itself, and introducing the other files. It tells Gems where its executable files are, gives a list of all its files, and as well as its name/date created/whatever else functions. It is the extroverted greeter of Rootdirectoryland. There’s also something called gitignore which seems to be the robots.txt of the git world.
At the end of my exhaustive tour, I feel I’ve gained a good sense of the basic files and what they do. Reconnaissance indicates that there are far more complicated structures out there, with folders packed with more folders, but hopefully this basic understanding will carry me through.
I had a computer science professor in college who would subtract massive amounts of points for improperly formatted code. This led to heroic tabbing on my part, but I always felt slightly resentful about it. It’s code! It runs the same whether you indent it or not! Computers don’t care, and these are the same OCD snobs that reject otherwise perfect code for want of a “;” or perhaps a misplaced “)”.
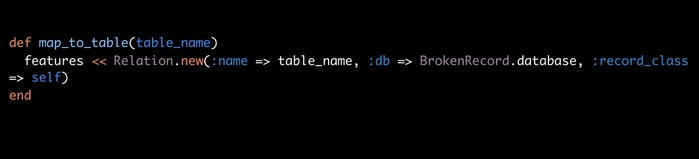
I was impressed, however, when I ran across this presentation on beautifully formatted Ruby on SpeakerDeck.com . It was really so…beautiful. Even a curmudgeon like myself could appreciate the difference between this:
and this:
Rather than slowly try to figure out which piece belongs to which, and what on Earth :record_class is, we have a simple, easy to understand block, with all the relations listed hierarchically, teaching us a great deal about the structure of the code, and the site it supports, in one glance. I’ve studied a bit of design and gotten a good appreciation for the importance of things like text alignment and style on the front end of web pages, but have rarely thought about the importance of style on the back end. This provides a fresh perspective – code doesn’t just exist to communicate with computers. After all, the best way to communicate with computers would be a series of 0s and 1s. It’s designed to communicate with programmers, and the same visual design rules apply, even if the public never sees it.
Group coding at The Flatiron School was new to me. I’ve had several jobs in the past that have involved coding, and they have never been exactly social. Generally, I would meet with non-techies to find out what kind of web thing they, and go back to my desk and make said thing. That was the entire action sequence. I learned a lot this way, in part because the nonprofits I worked for often had no one else on staff who could solve a problem. It was me and Google. I learned quite a bit this way, though this meant I had to learn much later in life not to write code that irritates other programmers. Someday, I shall introduce you to my session variable named George.
The biggest drawback to being a lone wolf is you completely miss the osmosis-type learning that occurs when you have other coders around you. If a technique did not come up when you were frantically searching Google for answers, you can easily miss it entirely. It’s also true that there’s no one to cross-examine you, and it’s easy to stop working once the damn thing works, even if it’s massively inefficient.
When I came to Flatiron, The closest I’ve ever come to collaborating with someone on a web endeavor has been something like “OK, you do the navigation, and I’ll do the footer.”
Pros
Different strengths
This includes the obvious, like people knowing languages you don’t know, but also people who think in a different way than you do. I’ve only been team coding for a week, and already there have been several times when I’ve watched others easily solve problems that had me staring blankly, and vice versa.
Your random eccentricities don’t seep into code as much
There’s no way you could get away with naming a variable George in a group.
It’s ridiculously easy to ask for help.
At Flatiron, we often hear a lecture on a topic and then go to code in a group, and if there’s something in the lecture I don’t understand, there’s always someone in the group who can explain it to me.
Group jokes!
We just wrote a program that tells the user it’s deleting their entire hard drive if they enter invalid input, and then stuck it on some likely marks. It was AMAZING. I occasionally tried to do this when I was on my own, but the joy did not compare. Jokes are funnier with many people in on them.
Cons
Other people’s random eccentricities sneak into the code, and you will not find them as charming as your own eccentricities
Even though it’s harder to put your own eccentric touch on code in a group (Hi, George!), you do sometimes get outvoted in a group, and then have to sit there as the group goes down what you view as a strange path. There is very little you can do about this.
When a group gets bogged down, it REALLY gets bogged down
Taking major coding detours as an individual is bad enough, but taking an irrelevant detour with the weight of four, really hard core people speeding along Detour Road means that you can get SERIOUSLY bogged down. You can write not only write test code to implement your detour, you can write four different versions of it, and then you can sit around discussing all of them for hours.
 The same logic works perfectly well for longitude, but I didn’t initially understand why we were returning latitude2 and longitude2, but then it hit me – latitude runs perfectly east-west, and longitude runs perfectly north-south. When they meet, they create a perfect right angle, and therefore, we can use….Pythagorean theorem. a2+b2=c2 . You can get the hypotenuse of a triangle by multiplying the lengths of its sides.
The same logic works perfectly well for longitude, but I didn’t initially understand why we were returning latitude2 and longitude2, but then it hit me – latitude runs perfectly east-west, and longitude runs perfectly north-south. When they meet, they create a perfect right angle, and therefore, we can use….Pythagorean theorem. a2+b2=c2 . You can get the hypotenuse of a triangle by multiplying the lengths of its sides.